Iz Beltagy
Google Scholar
Semantic Scholar
Twitter
GitHub
LinkedIn
Contact Me
I am a Co-founder and the Chief Scientist of spiffy.ai, a startup building intelligent systems that bring out the best in human capabilities.
I am a Lead Research Scientist at Allen Institute for AI (AI2) in the AllenNLP team, and the Research Lead of the OLMo project. OLMo aimes to build “state-of-the-art”, “truly-open” LLMs to narrow the gap between open and proprietary research. My role started with ideation and feasibility studies before the project’s inception, continuing through to the present where we now have a mature, large, corss-team project.
I received my PhD in Computer Science from the University of Texas at Austin working with Ray Mooney and Katrin Erk.
For the list of publications, please check my Semantic Scholar or Google Scholar pages.
Select Projects
-
OLMo A large cross-teams project at AI2 aiming to train truly open SOTA LLMs to narrow the gap between open and proprietary LLM research. https://allenai.org/olmo
-
TÜLU-1 and TÜLU-2 Instruction-tuned and DPO-based models outperforming llama-2 on a wide set of tasks. [Paper 1, 2], [Code].
-
DOLMA A state-of-the-art pretraining dataset of 3T tokens. [Blog]. [Data and Toolkit].
-
BLOOM - the open-source LLM from the BigScience project, which co-led its architecture and scaling group. [Architecture papers 1, 2], [Overview paper], [Model]
-
Can LMs learn “meaning” - TACL2022 paper led by Zhaofeng. [Paper]
-
Z-ICL - zero-shot ICL with pseudo-demonstrations. [Paper]
-
Staged Training - incrementally growing model size during pretraining. [Paper], [Code]
-
FLEX - principles of zero/few-shot NLP evaluation. [Paper] [Leaderboard] [Baseline model]
-
CDLM - a pretrained language model for cross-document proecssing. [Code and Pretrained Model]
-
MS2 - a large scale biomedical multi-document summarization dataset. [Code and Dataset]
-
LongformerEncoderDecoder (LED) - a pretrained transformer for long-document generation tasks. [Code and Pretrained model]
-
Longformer - a BERT-like model for long documents. [Code and Pretrained model]
-
SPECTER - a citation-informed embedding model for scintific documents. [Code, Data and Pretrained Model]
-
SciSpacy - a Spacy pipeline for scientific documents. [Code]
-
SciBERT - a BERT model for scientific documents. [Code, Data, and Pretrained model]
Updates
-
[5/2024] OLMo won the Innovation of the Year awared at GeekWire Awards! I had the privilege of accepting the award and delivering the speech. [GeekWire]. [Twitter].
-
[12/2023] Giving an invited talk at the NewSumm, EMNLP 2023 workshop.
-
[11/2023] Raised seed funding for my startup, https://spiffy.ai.
-
[10/2023] Gave a talk at the ELLIS LLM symposium about OLMo and open language models. [Slides].
-
[10/2023] Invited to serve as an Area Chair for EACL 2024.
-
[10/2023] Gave a guest lecture at Arman’s Foundation Models course.
-
[9/2023] Our TÜLU-1 paper is accepted for publishing at NeurIPS 2023 Datasets and Benchmarks Track. [Paper], [Code].
-
[8/2023] The DOLMA dataset is out. [Blog]. [Data and Toolkit].
-
[8/2023] Serving as an Area Chair for EMNLP 2023.
-
[7/2023] Promoted to Lead Research Scientist at AI2.
-
[7/2023] At ACL, 2023 in Toronto. Collaborators are presenting three papers [1], [2], [3].
-
[6/2023] An #NLPHighlights podcast about OLMo and open LLMs. Link.
-
[5/2023] Joined the panel discussion at the Playground RoboChat event to talk about AI and the tradeoff between scale and efficiency.
-
[5/2023] Rabeeh’s internship on diffusion is on arxiv. TESS: Text-to-Text Self-Conditioned Simplex Diffusion.
-
[3/2023] Research Lead of the OLMo project aiming to train “truly open” “SOTA” LLMs.
-
[2/2023] AI2 was offered 2M GPU hours from LUMI, thanks to Dirk’s efforts.
-
[1-3/2023] Conversations inside AI2 to discuss the necessity and feasibility of training our own LLMs.
-
[12/2022] At EMNLP in Abu Dhabi. Collaborators are presenting four papers [1], [2], [3], [4].
-
[7/2022] Gave a talk to The UKP Lab at the Technical University of Darmstadt. [Slides]
-
[6/2022] Invited to serve as AC for EMNLP 2022 for four tracks.
-
[6/2022] Serving as a standing reviewer for TACL.
-
[5/2022] An average of ~500 attended our tutorial, Zero- and Few-Shot NLP with Pretrained Language Models at ACL 2022. Slides. Videos (require ACL 2022 registration with Underline). Arman presenting part 6 of the tutorial.
-
[5/2022] Gave an invited talk with Julien Launay at the Challenges & Perspectives in Creating Large Language Models workshop, co-located with ACL 2022. [Slides].
-
[4/2022] Gave an invited talk at the Georgia Tech NLP seminar about Efficient Scaling of LM pretraining. [Slides]
-
[4/2022] Our paper What Language Model to Train if You Have One Million GPU Hours? is now available. It outlines the design and training setup of the BigScience language model.
-
[4/2022] Two papers accepted at Findings of NAACL 2022, LongChecker and Few-shot Self-Rationalization.
-
[3/2022] Our Staged Training paper is now available on arxiv. [Paper] [Code]
-
[3/2022] Training of the BigScience language model has started. The model is based on our paper here; an effor by the Architecture and Scaling group that I am co-chairing.
-
[12/2022] Wen Xiao, my intern with Arman won Intern of the Year award at AI2. Her paper on multi-document summarization has been accepted for publication at ACL 2022.
-
[12/2022] Our tutorial Zero- and Few-Shot NLP with Pretrained Language Models has been accepted to appear at ACL 2022.
-
[10/2021] Serving as an Action Editor for ACL Rolling Review
-
[9/2021] Our paper, FLEX has been accepted at NeurIPS 2021.
-
[9/2021] Our paper, SciCo won outstanding paper award at AKBC 2021.
-
[8/2021] Two EMNLP 2021 accepted papers; MS2 at the main conference and CDLM in the Findings of EMNLP.
-
[6/2021] Chairing the Architecture and Scaling group at the BigScience project aiming to train a 200B-parameter multilingual language model. [Recent slides]. [Weekly meeting calendar invite].
-
[5/2021] Joined the AllenNLP team at AI2.
-
[3/2021] Serving as an area chair for the ML for NLP track at EMNLP 2021.
-
[1/2021] Promoted to Senior Research Scientist at AI2.
-
[12/2020] Selected as an Outstanding Reviewer for EMNLP 2020.
-
[12/2020] LongformerEncoderDecoder (LED) is out. [Paper] [Code and Pretrained model]
-
[12/2020] Our tutorial “Beyond Paragraphs: NLP for Long Sequences” has been accepted to appear at NAACL 2021.
-
[11/2020] Co-organizing The Second Workshop on Scholarly Document Processing (SDP 2021).
-
[10/2020] Serving as an area chair for the Sentence-level Semantics and Textual Inference track at ACL 2021.
-
[10/2020] Serving as an area chair for the Sentence-level Semantics and Textual Inference track at NAACL 2021.
-
[9/2020] Serving as a publication co-chair for NAACL 2021.
-
[7/2020] Our paper, Don’t Stop Pretraining, won an honorary mention at ACL 2020.
-
[6/2020] Serving as a standing reviewer of Computational Linguistics (CL) journal.
-
[6/2020] Gave a talk about Longformer to UW NLP students [Slides]
-
[6/2020] Longformer is now integrated into the huggingface repo
-
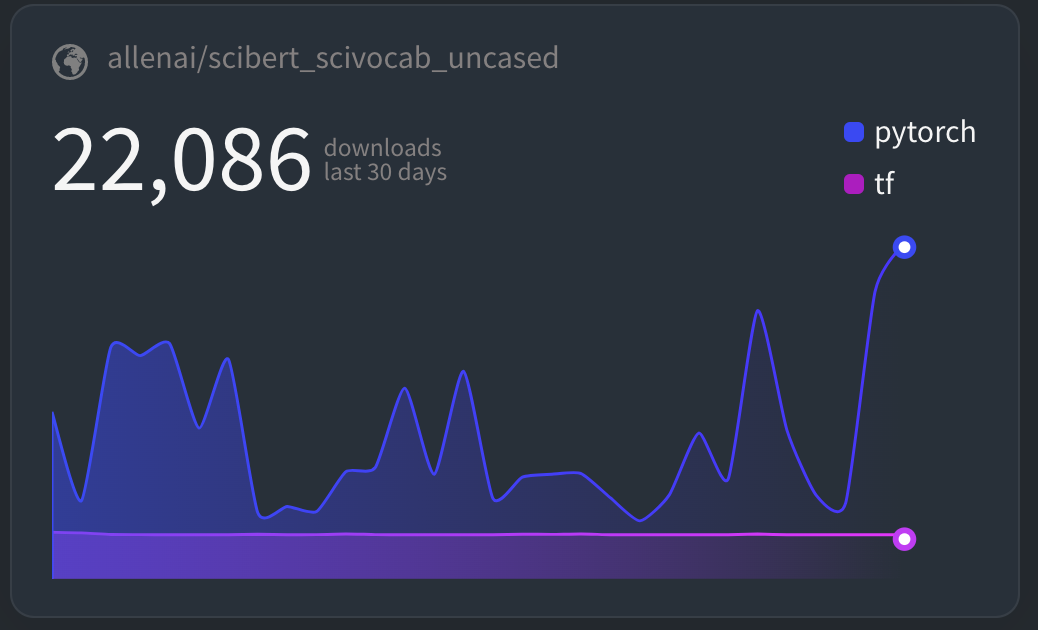
[5/2020] SciBERT has been downloaded more than 20,000 times in the last 30 days
-
[4/2020] Longformer is out
-
[3/2020] Co-organizing the SciNLP workshop. Check scinlp.org
{kind=link}
{kind=link}